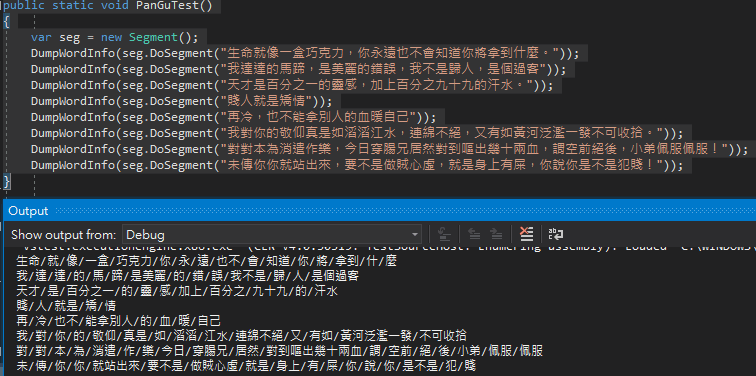
記錄自己遇到的蠢問題一枚。
抽象類別 Stream 常被當成輸入輸出參數 ,如此資料可以來自檔案、網路、記憶體或使用者自訂來源,還可套用裝飾者模式(Decorator Pattern)壓縮加密一次完成,提供強大彈性。實務上我常應用的情境是 ClosedXML/OpenXML SDK 之類原本要讀寫 Excel、Word 檔案的場合,函式接受檔案路徑或 Stream 以開啟現有檔案。遇到檔案保存於資料庫,取出的資料格式為 byte[],沒必要寫成暫存檔再開啟,我習慣用 new MemoryStream(byte[] data) 建立 MemoryStream,使用起來跟 FileStream 沒有兩樣。過去這個技巧我主要用在 ClosedXML 讀取 Excel 檔案,最近搬到 OpenXML SDK 操作修改 Word 內容,才發現這個程式寫法有問題。
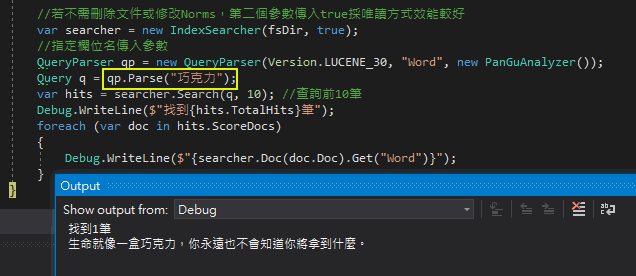
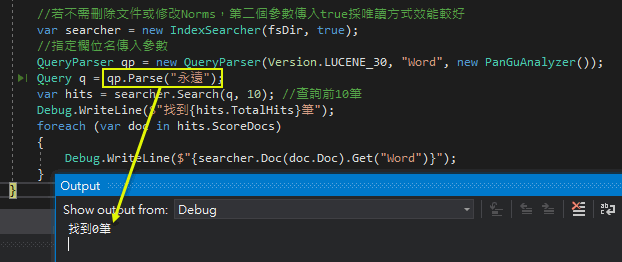
如下圖所示:
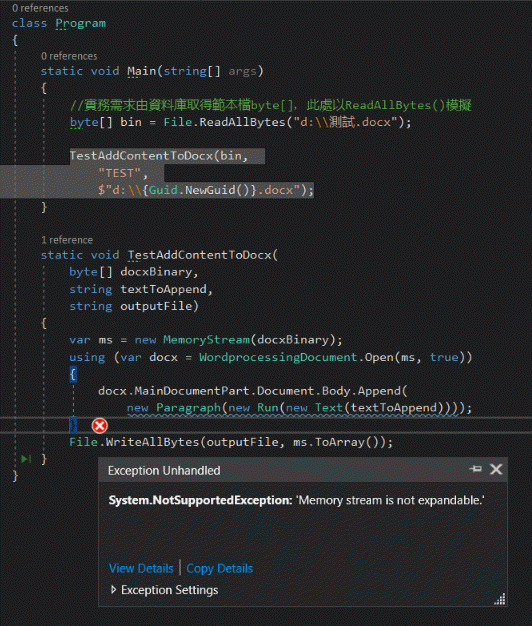
使用 new MemoryStream(byte[]) 建立的 Stream 可正確讀取 Word 文件檔,但在試圖新增內容時遇上「記憶體資料流是不可擴展的 / MemoryStream is not expandable」錯誤。
爬文發現我在這裡犯了一個低級錯誤,依據 MSDN 文件:
MemoryStream Constructor (Byte[])
Initializes a new non-resizable instance of the MemoryStream class based on the specified byte array.
傳入 byte[] 建構的 MemoryStream 大小是固定的,用於唯讀沒什麼問題,甚至只置換少量內容資料空間未變時也還過得去,但遇上要需要擴充大小就必死無疑。
var ms = new MemoryStream();ms.Write(bin, 0, bin.Length);
搞清楚問題根源,要修好不是難事! 如以上範例,先用 new MemoryStream() 建構可擴展的 MemoryStream,再用 .Write() 寫入 byte[] 內容,搞定收工!