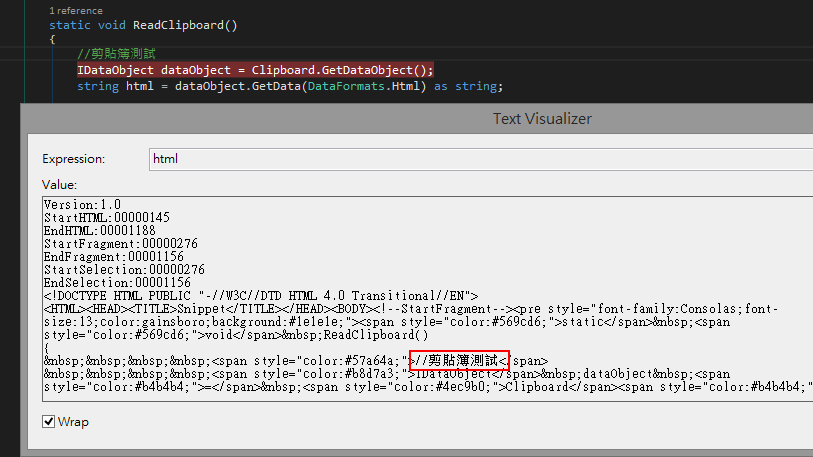
使用TypeScript處理AJAX呼叫時,常需要在前端定義與C#物件屬性一致的TypeScript型別,以便將後端傳來的JSON資料還原成強型別物件。針對較正式的資料模型,我會用CodeGen方式同步C#與TypeScript端的型別定義(順便處理多語系問題)。但蠻多時候處理對象只是零散的小型別,不必殺雞用牛刀,針對這類需求,推薦一個好用工具-TypeLITE。
在NuGet查關鍵字"typelite",很快就可找到TypeLite套件。
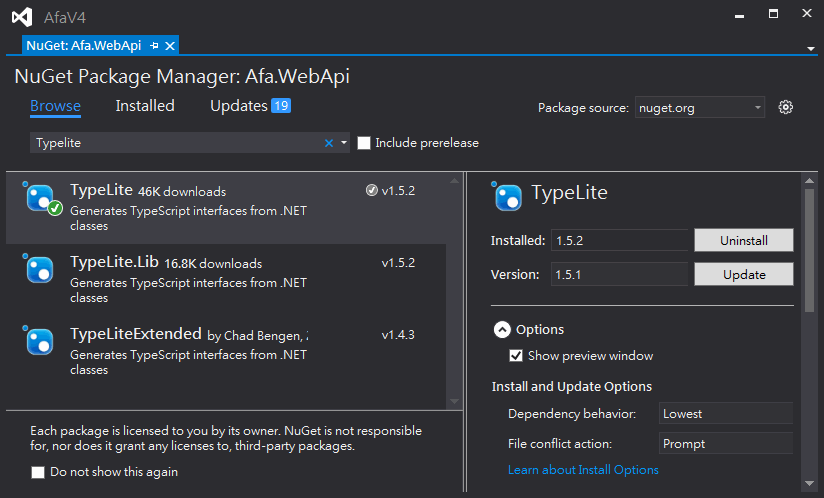
安裝後,專案會加入TypeLite.dll、TypeLIte.Net4.dll兩顆DLL,並在Scripts目錄下新増TypeLite.Net4.tt。接著就可以修改TypeLite.Net4.tt內容,決定為哪些型別產生TypeScript定義。
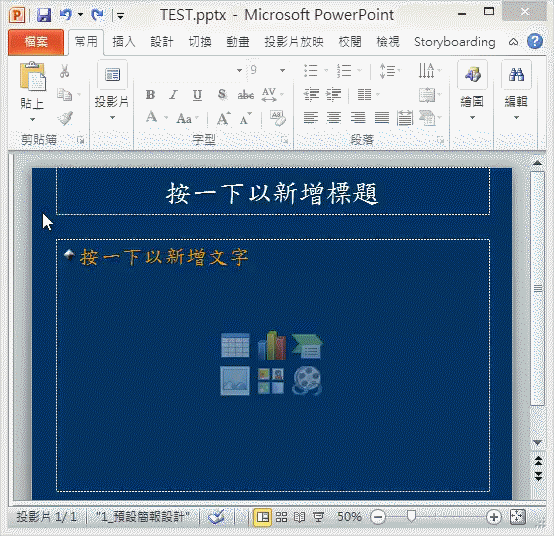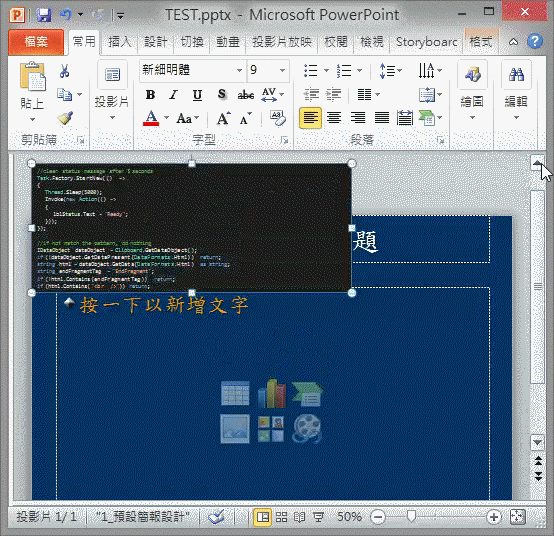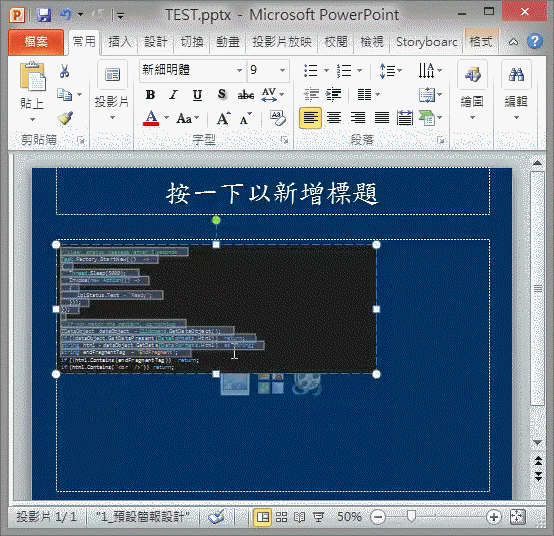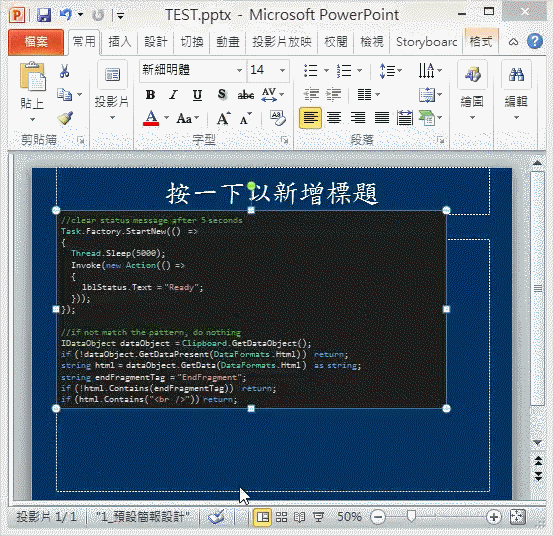
TypeLITE預設做法是執行.ForLoadedAssemblies()自動尋找組件標註[TsClass] Attribute的型別,但實務上用.For<型別名稱>()列舉要轉換的型別(如紅框所示)比較方便;若型別來自網站專案以外的組件,記得要加上<#@ assembly #>宣告(如黃框所示)。
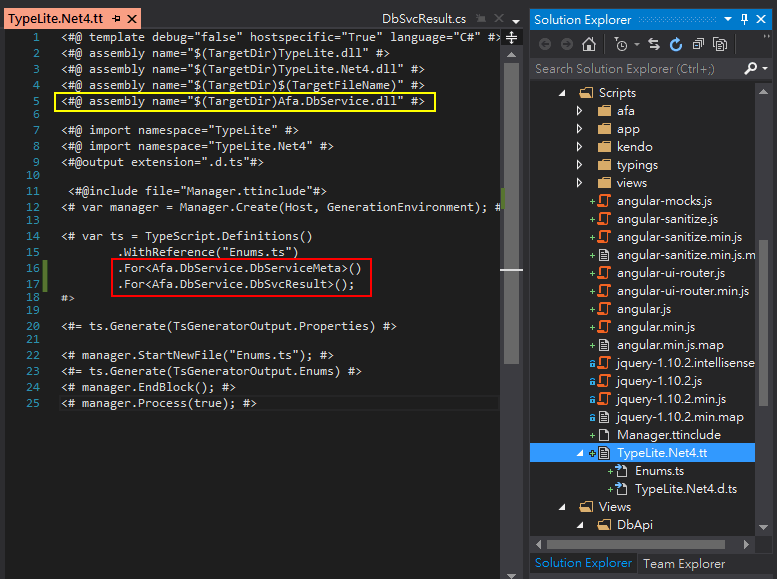
修改TypeLite.Net4.tt並存檔,T4工具將自動產生或更新TypeLite.Net4.d.ts,在其中可看到我們用.For<型別名稱>()所列舉型別的TypeScript介面定義,若型別有參照到其他型別,TypeLITE會自動包含進來,非常方便。(在範例中用到Reflection的MethodInfo,相關介面就像提棕子一般整串被拉進來。)
TypeScript定義檔僅在開發編譯階段提供強型別約束及提示,不會產生任何JavaScript,不用擔心TypeLite.Net4.d.ts的內容太複雜。就這樣,輕輕鬆鬆幾個步驟,就把C#端的型別定義搬到TypeScript端囉~
又到了呼口號時間:TypeLITE,好用!好用!好用!