分享同事踩到的 SELECT * 地雷一枚。
大家應該在程式設計準則都看過這條-「避免使用 SELECT * FROM Table,應以 SELECT Col1, Col2… 明確列舉欄位…」。
如此建議必有其考量:第一個理由顯而易見,正向表列必要欄位,可避免在網路傳送用不到的資料浪費頻寬,並能減少客戶端、伺服器端處理多餘資料的資源損耗。再者,查詢欄位多寡也可能影響效能,SELECT * 時為牽就非必要欄位,資料庫可能改用較無效率的索引,不利效能最佳化。還有一種極端情境,若所需欄位都存在於 Non-Clustered Index,即便使用的索引相同,SELECT * 迫使資料庫逐筆再 Key Lookup 取回完整資料列,拖累執行計劃並衍生非必要 IO。
另外,未正向列舉欄位在 Schema 變動時容易造成問題。例如:INSERT INTO TableA SELECT * FROM TableB,一旦 TableA 或 TableB 欄位增減或調換順序就會出錯。應寫成 INSERT INTO TableA (C1,C2,C3) SELECT C1,C2,C3 FROM TableB 才嚴謹。
以上均為我已知效能問題或嚴謹性疏失,但這次的案例讓我有些意外,是一個 View 使用 SELECT * 導致 Schema 一變更就爆炸的個案!
使用以下案例重現問題:
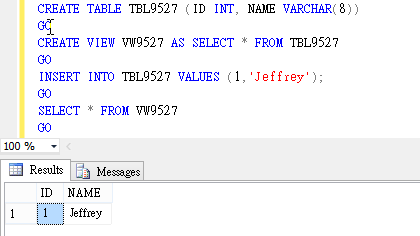
有一個具備 ID、NAME 兩個欄位的資料表 TBL9527,另外有 View VW9527,內容為 SELECT * FROM TBL9527。塞入一筆資料並查詢 VW9527,結果符合預期:
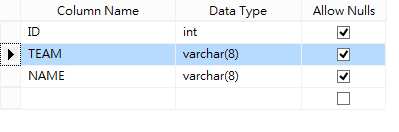
修改 TBL9527,在 ID 與 NAME 欄位間插入一個 TEAM 欄位。
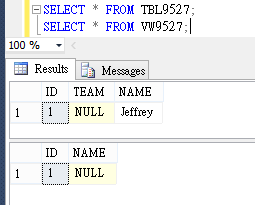
猜猜怎麼了?SELECT * FROM TBL9527 結果正常,但 VW9527 查詢結果的 NAME 對應成 TEAM,内容為 NULL!
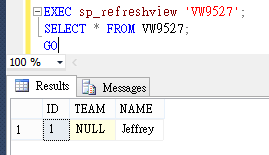
要修正問題,需執行 EXEC sp_RefreshView'VW9527' 更新 View 的 Metadata。
咦~ 在 View 使用 SELECT * 的朋友愛自意哦!
【參考資料】
- SELECT - Vs. SELECT COLUMNS – SQL Server Optimization Techniques - Learn SQL
- My view isn’t reflecting changes I’ve made to the underlying tables. - SQL Studies
- Why you shouldn’t use SELECT - - SQL Studies